

 个人中心
个人中心 退出
退出




MySQL 8.0 新特性之窗口函数
作者: 不剪发的Tony老师
毕业于北京航空航天大学,十多年数据库管理与开发经验,目前在一家全球性的金融公司从事数据库架构设计。CSDN学院签约讲师以及GitChat专栏作者。csdn上的博客收藏于以下地址:https://tonydong.blog.csdn.net
文章目录
窗口函数概述
窗口函数语法
PARTITION BY
ORDER BY
窗口选项
命名窗口
窗口函数列表
聚合窗口函数
专用窗口函数
窗口函数限制
窗口函数优化
大家好!我是只谈技术不剪发的 Tony 老师。今天给大家分享 MySQL 8.0 中的一个新特性:窗口函数。
许多关系型数据库,例如 Oracle、SQL Server、PostgreSQL 以及 SQLite 等,都实现了 SQL 标准定义的窗口函数;MySQL 8.0 终于也增加了这个功能,今天我们就来详细介绍一下 MySQL 中的窗口函数。
这里是一份 SQL 窗口函数速查表,可以方便我们快速回顾和查找相关信息。
窗口函数概述
窗口函数(Window Function)针对查询中的每一行数据,基于和它相关的一组数据计算出一个结果。窗口函数在某些数据库中也叫做分析函数(Analytic Function)。
为了便于理解,我们可以比较一下聚合函数和窗口函数的区别。首先创建一个销售数据示例表 sales:
CREATE TABLE sales
(
year INT,
country VARCHAR(20),
product VARCHAR(32),
profit INT
);
insert into sales(year, country, product, profit)
values
(2000, 'Finland', 'Computer', 1500),
(2001, 'USA', 'Computer', 1200),
(2001, 'Finland', 'Phone', 10),
(2000, 'India', 'Calculator', 75),
(2001, 'USA', 'TV', 150),
(2000, 'India', 'Computer', 1200),
(2000, 'USA', 'Calculator', 75),
(2000, 'USA', 'Computer', 1500),
(2000, 'Finland', 'Phone', 100),
(2001, 'USA', 'Calculator', 50),
(2001, 'USA', 'Computer', 1500),
(2000, 'India', 'Calculator', 75),
(2001, 'USA', 'TV', 100);
以下是 SUM 函数分别作为聚合函数和窗口函数的结果:
mysql> SELECT SUM(profit) AS total_profit FROM sales;
+--------------+
| total_profit |
+--------------+
| 7535 |
+--------------+
1 row in set (0.00 sec)
SELECT year, country, product, profit,
SUM(profit) OVER() AS total_profit
FROM sales;
mysql> SELECT year, country, product, profit,
-> SUM(profit) OVER() AS total_profit
-> FROM sales;
+------+---------+------------+--------+--------------+
| year | country | product | profit | total_profit |
+------+---------+------------+--------+--------------+
| 2000 | Finland | Computer | 1500 | 7535 |
| 2001 | USA | Computer | 1200 | 7535 |
| 2001 | Finland | Phone | 10 | 7535 |
| 2000 | India | Calculator | 75 | 7535 |
| 2001 | USA | TV | 150 | 7535 |
| 2000 | India | Computer | 1200 | 7535 |
| 2000 | USA | Calculator | 75 | 7535 |
| 2000 | USA | Computer | 1500 | 7535 |
| 2000 | Finland | Phone | 100 | 7535 |
| 2001 | USA | Calculator | 50 | 7535 |
| 2001 | USA | Computer | 1500 | 7535 |
| 2000 | India | Calculator | 75 | 7535 |
| 2001 | USA | TV | 100 | 7535 |
+------+---------+------------+--------+--------------+
13 rows in set (0.00 sec)
从查询的结果可以看出,窗口函数 SUM(profit) OVER() 执行了和聚合函数 SUM(profit) 类似的汇总。不过聚合函数只返回了一个汇总之后的结果,而窗口函数为每一行数据都返回了结果。
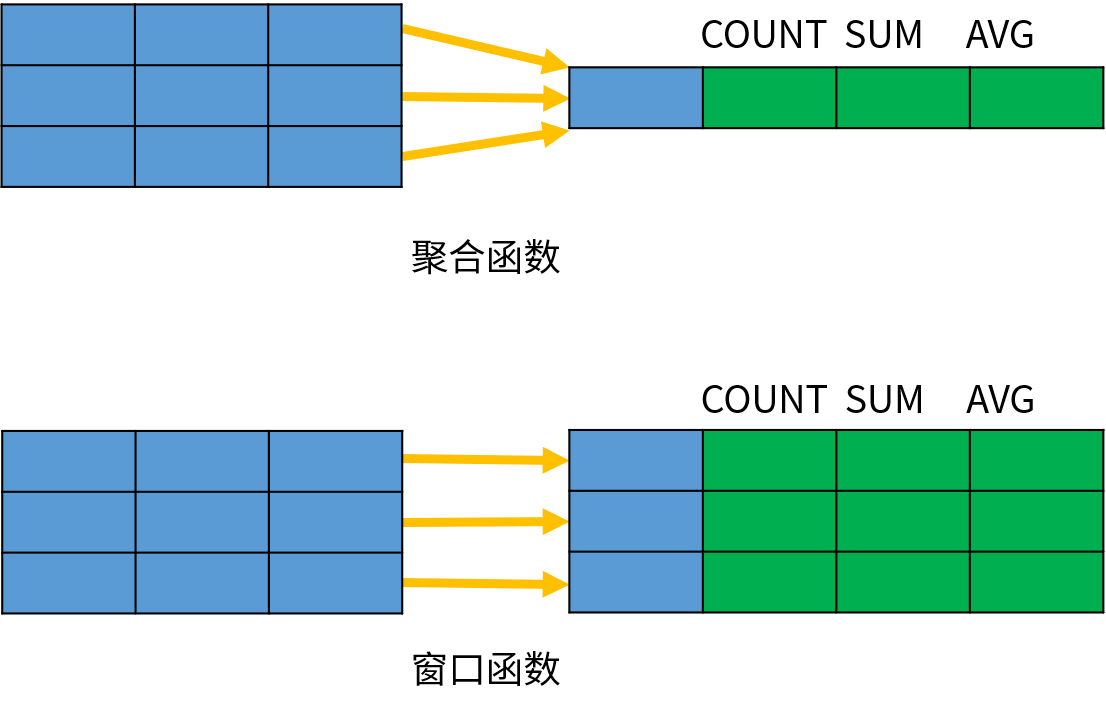
窗口函数只能出现在 SELECT 列表和 ORDER BY 子句中,查询语句的处理顺序依次为 FROM、WHERE、GROUP BY、聚合函数、HAVING、窗口函数、SELECT DISTINCT、ORDER BY、LIMIT。
窗口函数与其他函数的语法区别主要在于 OVER 子句,接下来我们介绍它的语法。
窗口函数语法
窗口函数的语法如下:
window_function(expr)
OVER (
PARTITION BY ...
ORDER BY ...
frame_clause
)
OVER 子句包含三个可选项:分区(PARTITION BY)、排序(ORDER BY)以及窗口大小(frame_clause)。
PARTITION BY
PARTITION BY 选项用于将数据行拆分成多个分区(组),窗口函数基于每一行数据所在的组进行计算并返回结果。如果省略了 PARTITION BY,所有的数据作为一个组进行计算。在上面的示例中,SUM(profit) OVER() 就是将所有的销售数据看作一个分区。
下面的查询按照不同的国家汇总销量:
mysql> SELECT year, country, product, profit,
-> SUM(profit) OVER(PARTITION BY country) AS country_profit
-> FROM sales;
+------+---------+------------+--------+----------------+
| year | country | product | profit | country_profit |
+------+---------+------------+--------+----------------+
| 2000 | Finland | Computer | 1500 | 1610 |
| 2001 | Finland | Phone | 10 | 1610 |
| 2000 | Finland | Phone | 100 | 1610 |
| 2000 | India | Calculator | 75 | 1350 |
| 2000 | India | Computer | 1200 | 1350 |
| 2000 | India | Calculator | 75 | 1350 |
| 2001 | USA | Computer | 1200 | 4575 |
| 2001 | USA | TV | 150 | 4575 |
| 2000 | USA | Calculator | 75 | 4575 |
| 2000 | USA | Computer | 1500 | 4575 |
| 2001 | USA | Calculator | 50 | 4575 |
| 2001 | USA | Computer | 1500 | 4575 |
| 2001 | USA | TV | 100 | 4575 |
+------+---------+------------+--------+----------------+
13 rows in set (0.00 sec)
SQL 标准要求 PARTITION BY 之后只能使用字段名,不过 MySQL 允许指定表达式。例如,假设表中存在一个名为 ts 的 TIMESTAMP 类型字段,SQL 表中允许 PARTITION BY ts 但是不允许 PARTITION BY HOUR(ts);而 MySQL 两者都允许。
另外,我们也可以指定多个分组字段:
PARTITION BY expr [, expr] ...
ORDER BY
ORDER BY 选项用于指定分区内数据的排序,排序字段数据相同的行是对等行(peer)。如果省略 ORDER BY ,分区内的数据不进行排序,不按照固定顺序处理, 而且所有数据都是对等行。ORDER BY 通常用于排名分析函数,参考下文中的专用窗口函数。
以下查询按照国家进行分组,按照年份和产品名称进行排序,然后汇总销量:
mysql> SELECT year, country, product, profit,
-> SUM(profit) OVER(PARTITION BY country ORDER BY year, product) AS country_profit
-> FROM sales;
+------+---------+------------+--------+----------------+
| year | country | product | profit | country_profit |
+------+---------+------------+--------+----------------+
| 2000 | Finland | Computer | 1500 | 1500 |
| 2000 | Finland | Phone | 100 | 1600 |
| 2001 | Finland | Phone | 10 | 1610 |
| 2000 | India | Calculator | 75 | 150 |
| 2000 | India | Calculator | 75 | 150 |
| 2000 | India | Computer | 1200 | 1350 |
| 2000 | USA | Calculator | 75 | 75 |
| 2000 | USA | Computer | 1500 | 1575 |
| 2001 | USA | Calculator | 50 | 1625 |
| 2001 | USA | Computer | 1200 | 4325 |
| 2001 | USA | Computer | 1500 | 4325 |
| 2001 | USA | TV | 150 | 4575 |
| 2001 | USA | TV | 100 | 4575 |
+------+---------+------------+--------+----------------+
13 rows in set (0.00 sec)
ORDER BY 之后的表达式也可以使用 ASC 或者 DESC 指定排序方式,默认为 ASC。对应升序排序,NULL 排在最前面;对于降序排序,NULL 排在最后面:
ORDER BY expr [ASC|DESC] [, expr [ASC|DESC]] ...
OVER 子句中的 ORDER BY 选项只用于分区内的数据排序;如果想要对最终的结果进行排序,可以使用 ORDER BY 子句。
窗口选项
frame_clause 选项用于在当前分区中指定一个数据窗口,也就是一个与当前行相关的数据子集。窗口会随着当前处理的数据行而移动,例如:
定义一个从分区开始到当前数据行结束的窗口,可以计算截止到每一行的累计总值。
定义一个从当前行之前 N 行数据到当前行之后 N 行数据的窗口,可以计算移动平均值。
frame_clause 的语法如下:
{ROWS | RANGE} frame_start
{ROWS | RANGE} BETWEEN frame_start AND frame_end
其中,
ROWS 表示通过开始行和结束行的位置指定窗口,偏移量以行数为单位进行计算。
RANGE 表示通过开始行和结束行的数值指定窗口,偏移量以数值为单位进行计算。
frame_start 和 frame_end 分别表示窗口的开始行和结束行。如果只有 frame_start,默认以当前行作为窗口的结束。
CURRENT ROW
UNBOUNDED PRECEDING
UNBOUNDED FOLLOWING
expr PRECEDING
expr FOLLOWING

如果同时指定了两者,frame_start 不能晚于 frame_end,例如 BETWEEN 1 FOLLOWING AND 1 PRECEDING 就是一个无效的窗口。
frame_start 和 frame_end 的具体意义如下:
CURRENT ROW:对于 ROWS 方式,代表了当前行;对于 RANGE,代表了当前行的所有对等行。
UNBOUNDED PRECEDING:代表了分区中的第一行。
UNBOUNDED FOLLOWING:代表了分区中的最后一行。
expr PRECEDING:对于 ROWS 方式,代表了当前行之前的第 expr 行;对于 RANGE,代表了等于当前行的值减去 expr 的所有行;如果当前行的值为 NULL,代表了当前行的所有对等行。
expr FOLLOWING:对于 ROWS 方式,代表了当前行之后的第 expr 行;对于 RANGE,代表了等于当前行的值加上 expr 的所有行;如果当前行的值为 NULL,代表了当前行的所有对等行。
对于 expr PRECEDING 和 expr FOLLOWING),expr 可以是一个 ? 参数占位符(用于预编译语句)、非负的数值常量或者 INTERVAL val unit 格式的时间间隔。对于 INTERVAL 表达式,val 是一个非负的时间间隔值,unit 是一个时间间隔单位,例如 INTERVAL 1 DAY。关于时间间隔常量的详细信息,可以参考官方文档中的 DATE_ADD() 函数介绍。
基于数字或者时间间隔的 RANGE 窗口需要指定一个基于数字或者时间间隔的 ORDER BY。以下是一些有效的 expr PRECEDING 和 expr FOLLOWING 窗口:
10 PRECEDING
INTERVAL 5 DAY PRECEDING
5 FOLLOWING
INTERVAL '2:30' MINUTE_SECOND FOLLOWING
以下查询演示了如何实现累计求和以及移动平均值:
mysql> SELECT year, country, product, profit,
-> SUM(profit) OVER(PARTITION BY country ORDER BY year, product ROWS UNBOUNDED PRECEDING) AS running_total,
-> AVG(profit) OVER(PARTITION BY country ORDER BY year,
product ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS running_average
-> FROM sales;
+------+---------+------------+--------+---------------+-----------------+
| year | country | product | profit | running_total | running_average |
+------+---------+------------+--------+---------------+-----------------+
| 2000 | Finland | Computer | 1500 | 1500 | 800.0000 |
| 2000 | Finland | Phone | 100 | 1600 | 536.6667 |
| 2001 | Finland | Phone | 10 | 1610 | 55.0000 |
| 2000 | India | Calculator | 75 | 75 | 75.0000 |
| 2000 | India | Calculator | 75 | 150 | 450.0000 |
| 2000 | India | Computer | 1200 | 1350 | 637.5000 |
| 2000 | USA | Calculator | 75 | 75 | 787.5000 |
| 2000 | USA | Computer | 1500 | 1575 | 541.6667 |
| 2001 | USA | Calculator | 50 | 1625 | 916.6667 |
| 2001 | USA | Computer | 1200 | 2825 | 916.6667 |
| 2001 | USA | Computer | 1500 | 4325 | 950.0000 |
| 2001 | USA | TV | 150 | 4475 | 583.3333 |
| 2001 | USA | TV | 100 | 4575 | 125.0000 |
+------+---------+------------+--------+---------------+-----------------+
13 rows in set (0.01 sec)
对于 running_average,每个分区内的第一行数据没有 PRECEDING,结果是当前行和下一行的平均值;最后一行数据没有 FOLLOWING,结果是当前行和上一行的平均值。
另外,这篇文章介绍了如何基于时间间隔指定窗口大小,从而实现银行等金融机构可疑支付交易的监测。
如果没有指定 frame_clause,默认的窗口取决于是否存在 ORDER BY 选项:
如果指定了 ORDER BY:默认窗口从分区的开始直到当前行,包括当前行的所有对等行。此时默认窗口相当于:RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW;
如果没有指定 ORDER BY:默认窗口就是整个分区,因为此时所有的数据都是对等行。此时默认窗口相当于:RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING。
由于默认窗口取决于是否包含了 ORDER BY 选项,而增加 ORDER BY 获得确定结果的同时又可能改变结果(例如 SUM() 函数的结果就会因此而改变)。所以,为了获得相同的结果,但又按照 ORDER BY 排序,可以总是明确指定一个窗口选项。
如果当前行的数据为 NULL,窗口的定义可能不太明确。以下示例说明了这种情况下各种窗口选项的作用:
ORDER BY X ASC RANGE BETWEEN 10 FOLLOWING AND 15 FOLLOWING,窗口从 NULL 开始到 NULL 结束,也就是说窗口只包含 NULL 数据。
ORDER BY X ASC RANGE BETWEEN 10 FOLLOWING AND UNBOUNDED FOLLOWING,窗口从 NULL 开始到分区的最后结束。由于 ASC 排序时 NULL 值出现在最前面,因此窗口就是整个分区。
ORDER BY X DESC RANGE BETWEEN 10 FOLLOWING AND UNBOUNDED
FOLLOWING,窗口从 NULL 开始到分区的最后结束。由于 DESC 排序时 NULL 值出现在最后面,因此窗口只包含 NULL 数据。
ORDER BY X ASC RANGE BETWEEN 10 PRECEDING AND UNBOUNDED FOLLOWING,窗口从 NULL 开始到分区的最后结束。由于 ASC 排序时 NULL 值出现在最前面,因此窗口就是整个分区。
ORDER BY X ASC RANGE BETWEEN 10 PRECEDING AND 10 FOLLOWING,窗口从 NULL 开始到 NULL 结束,也就是说窗口只包含 NULL 数据。
ORDER BY X ASC RANGE BETWEEN 10 PRECEDING AND 1 PRECEDING,窗口从 NULL 开始到 NULL 结束,也就是说窗口只包含 NULL 数据。
ORDER BY X ASC RANGE BETWEEN UNBOUNDED PRECEDING AND 10
FOLLOWING,窗口从分区的第一行开始到 NULL 结束。由于 ASC 排序时 NULL 值出现在最前面,因此窗口只包含 NULL 数据。
命名窗口
OVER 子句除了直接定义各种选项之外,还可以使用一个预定义的窗口变量。窗口变量使用 WINDOW 子句进行定义,语法上位于 HAVING 和 ORDER BY 之间。
window_function(expr) OVER window_name
WINDOW window_name AS (PARTITION BY ... ORDER BY ... frame_clause)
WINDOW window_name AS (other_window_name)
如果查询中多个窗口函数的 OVER 子句相同,利用 WINDOW 子句定义一个窗口变量,然后在多个 OVER 子句中使用该变量可以简化查询语句:
SELECT year, country, product, profit,
SUM(profit) OVER w AS country_total,
AVG(profit) OVER w AS country_average,
COUNT(profit) OVER w AS country_count
FROM sales
WINDOW w AS (PARTITION BY country);
如果需要修改窗口的定义,这种方式只需要修改一次,更加方便。
OVER 子句还可以使用 OVER (window_name …) 基于已有的窗口变量进行修改,但是只能增加其他选项。例如,以下查询定义了一个窗口变量,指定了分区选项;然后在 OVER 子句中增加了不同的 ORDER BY 选项:
SELECT year, country, product, profit,
SUM(profit) OVER (w ORDER BY year, product ROWS UNBOUNDED PRECEDING) AS running_total,
AVG(profit) OVER (w ORDER BY year, product ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS running_average,
COUNT(profit) OVER w AS country_count
FROM sales
WINDOW w AS (PARTITION BY country);
OVER 子句只能为窗口变量增加选项,而不能修改原来的选项。以下是一个错误的示例:
OVER (w PARTITION BY year)
... WINDOW w AS (PARTITION BY country)
另外,窗口变量的定义中也可以使用其他窗口变量。例如:
WINDOW w1 AS (w2), w2 AS (), w3 AS (w1)
w1 反向引用了 w2,w3 正向引用了 w1。但是注意不要产生循环引用,例如以下定义将会产生错误:
WINDOW w1 AS (w2), w2 AS (w3), w3 AS (w1)
w1、w2、w3 之间是一个循环引用,无法真正定义窗口变量。
窗口函数列表
MySQL 中的窗口函数可以分为两类:聚合窗口函数和专用窗口函数。
聚合窗口函数
许多 MySQL 聚合函数都支持 OVER 子句,从而作为窗口函数使用:
AVG(),计算平均值;
BIT_AND(),按位与运算;
BIT_OR(),按位或运算;
BIT_XOR(),按位异或运算;
COUNT(),计算行数;
JSON_ARRAYAGG(),以 JSON 数组返回数据;
JSON_OBJECTAGG(),以 JSON 对象返回数据;
MAX(),计算最大值;
MIN(),计算最小值;
STDDEV_POP()、STDDEV()、STD(),计算总体标准差;
STDDEV_SAMP(),计算样本标准差;
SUM(),计算和值;
VAR_POP()、VARIANCE(),计算总体方差;
VAR_SAMP(),计算样本方差。
聚合窗口函数基于当前行所在的窗口进行计算,窗口的定义和默认值可以参考上文中的窗口选项。关于这些聚合窗口函数的具体介绍,可以参考官方文档。
专用窗口函数
MySQL 提供了以下专用的窗口函数:
CUME_DIST(),返回累积分布值,也就是分区内小于等于当前行的数据行占比。取值范围 [0, 1];
DENSE_RANK(),返回当前行在分区内的排名,数据相同的行排名相同,随后的排名不会产生跳跃;
FIRST_VALUE(),返回当前窗口内的第一行;
LAG(),返回分区内当前行上面(之前)的第 N 行;
LAST_VALUE(),返回当前窗口内的最后一行;
LEAD(),返回分区内当前行下面(之后)的第 N 行;
NTH_VALUE(),返回当前窗口内的第 N 行;
NTILE(),将当前分区拆分成 N 个组,返回当前行所在的组编号;
PERCENT_RANK(),返回分区内排除最高值之后,小于当前行的数据行占比,计算方式为 (rank - 1) / (rows - 1);
RANK(),返回当前行在分区内的排名,数据相同的行排名相同,随后的排名会产生跳跃;
ROW_NUMBER(),返回当前行在分区内的编号,从 1 开始。
以下窗口函数基于当前行所在的窗口进行计算:
FIRST_VALUE()
LAST_VALUE()
NTH_VALUE()
以下函数基于整个分区进行计算:
CUME_DIST()
DENSE_RANK()
LAG()
LEAD()
NTILE()
PERCENT_RANK()
RANK()
ROW_NUMBER()
SQL 标准不允许这些函数指定窗口选项,MySQL 允许为它们指定窗口选项,但是会忽略这些选项。
以下是一些用于排名的窗口函数示例:
mysql> SELECT year, country, product, profit,
-> ROW_NUMBER() OVER(PARTITION BY country ORDER BY profit DESC) AS "row_number",
-> RANK() OVER(PARTITION BY country ORDER BY profit DESC) AS "rank",
-> DENSE_RANK() OVER(PARTITION BY country ORDER BY profit DESC) AS "dense_rank",
-> PERCENT_RANK() OVER(PARTITION BY country ORDER BY profit DESC) AS "percent_rank"
-> FROM sales;
+------+---------+------------+--------+------------+------+------------+--------------------+
| year | country | product | profit | row_number | rank | dense_rank | percent_rank |
+------+---------+------------+--------+------------+------+------------+--------------------+
| 2000 | Finland | Computer | 1500 | 1 | 1 | 1 | 0 |
| 2000 | Finland | Phone | 100 | 2 | 2 | 2 | 0.5 |
| 2001 | Finland | Phone | 10 | 3 | 3 | 3 | 1 |
| 2000 | India | Computer | 1200 | 1 | 1 | 1 | 0 |
| 2000 | India | Calculator | 75 | 2 | 2 | 2 | 0.5 |
| 2000 | India | Calculator | 75 | 3 | 2 | 2 | 0.5 |
| 2000 | USA | Computer | 1500 | 1 | 1 | 1 | 0 |
| 2001 | USA | Computer | 1500 | 2 | 1 | 1 | 0 |
| 2001 | USA | Computer | 1200 | 3 | 3 | 2 | 0.3333333333333333 |
| 2001 | USA | TV | 150 | 4 | 4 | 3 | 0.5 |
| 2001 | USA | TV | 100 | 5 | 5 | 4 | 0.6666666666666666 |
| 2000 | USA | Calculator | 75 | 6 | 6 | 5 | 0.8333333333333334 |
| 2001 | USA | Calculator | 50 | 7 | 7 | 6 | 1 |
+------+---------+------------+--------+------------+------+------------+--------------------+
13 rows in set (0.00 sec)
注意不同函数的排名方式。
以下是一些用于获取指定数据行值的窗口函数示例:
mysql> SELECT year, country, product, profit,
-> LEAD(profit, 1, 0) OVER(PARTITION BY country ORDER BY profit DESC) AS "lead",
-> LAG(profit, 1, 0) OVER(PARTITION BY country ORDER BY profit DESC) AS "lag",
-> FIRST_VALUE(profit) OVER(PARTITION BY country ORDER BY profit DESC) AS "first_value",
-> LAST_VALUE(profit) OVER(PARTITION BY country ORDER BY profit DESC) AS "last_value",
-> NTH_VALUE(profit, 2) OVER(PARTITION BY country ORDER BY profit DESC) AS "nth_value"
-> FROM sales;
+------+---------+------------+--------+------+------+-------------+------------+-----------+
| year | country | product | profit | lead | lag | first_value | last_value | nth_value |
+------+---------+------------+--------+------+------+-------------+------------+-----------+
| 2000 | Finland | Computer | 1500 | 100 | 0 | 1500 | 1500 | NULL |
| 2000 | Finland | Phone | 100 | 10 | 1500 | 1500 | 100 | 100 |
| 2001 | Finland | Phone | 10 | 0 | 100 | 1500 | 10 | 100 |
| 2000 | India | Computer | 1200 | 75 | 0 | 1200 | 1200 | NULL |
| 2000 | India | Calculator | 75 | 75 | 1200 | 1200 | 75 | 75 |
| 2000 | India | Calculator | 75 | 0 | 75 | 1200 | 75 | 75 |
| 2000 | USA | Computer | 1500 | 1500 | 0 | 1500 | 1500 | 1500 |
| 2001 | USA | Computer | 1500 | 1200 | 1500 | 1500 | 1500 | 1500 |
| 2001 | USA | Computer | 1200 | 150 | 1500 | 1500 | 1200 | 1500 |
| 2001 | USA | TV | 150 | 100 | 1200 | 1500 | 150 | 1500 |
| 2001 | USA | TV | 100 | 75 | 150 | 1500 | 100 | 1500 |
| 2000 | USA | Calculator | 75 | 50 | 100 | 1500 | 75 | 1500 |
| 2001 | USA | Calculator | 50 | 0 | 75 | 1500 | 50 | 1500 |
+------+---------+------------+--------+------+------+-------------+------------+-----------+
13 rows in set (0.00 sec)
关于这些窗口函数的具体介绍,可以参考官方文档。
窗口函数限制
SQL 标准不允许在 UPDATE 或者 DELETE 语句中使用窗口函数更新数据,但是允许在子查询中使用这些函数。
MySQL 目前不支持 SQL 标准中定义的以下功能:
聚合创建函数中的 DISTINCT 关键字;
嵌套窗口函数;
基于当前行数据值的动态窗口。
MySQL 解析器可以接收以下标准 SQL 选项但是不会生效:
以 GROUPS 为单位的窗口选项会产生错误,目前只支持 ROWS 和 RANGE 方式;
指定窗口时的 EXCLUDE 选项会产生错误;
使用 IGNORE NULLS 选项会产生错误,目前只支持 RESPECT NULLS;
使用 FROM LAST 选项会产生错误,目前只支持 FROM FIRST。
窗口函数优化
窗口函数会对优化器产生以下影响:
如果子查询中包含窗口函数,就不会使用派生表合并优化。此时子查询只会使用物化进行优化。
半连接不能用于窗口函数优化,因为半连接只能用于 WHERE 和 JOIN … ON 子查询,它们不能包含窗口函数。
优化器按照顺序处理多个具有相同排序规则的窗口,因此除了第一个窗口,其他都可以省略排序操作。
优化器不会尝试合并多个原本可以一次获取的窗口,例如多个定义完全相同的 OVER 子句。解决办法就是通过 WINDOW 子句定义一个窗口变量,然后在多个 OVER 子句中进行引用。
聚合函数不作为窗口函数使用时,会在尽可能的最外层查询执行聚合操作。例如,以下查询中,MySQL 知道 COUNT(t1.b) 不是外部查询中的聚合函数,因为它属于 WHERE 子句:
SELECT * FROM t1 WHERE t1.a = (SELECT COUNT(t1.b) FROM t2);
所以,MySQL 在子查询中进行聚合操作,将 t1.b 看作一个常量并且返回 t2 中的数据行数。
如果将 WHERE 替换成 HAVING 将会导致错误:
mysql> SELECT * FROM t1 HAVING t1.a = (SELECT COUNT(t1.b) FROM t2);
ERROR 1140 (42000): In aggregated query without GROUP BY, expression #1
of SELECT list contains nonaggregated column 'test.t1.a'; this is
incompatible with sql_mode=only_full_group_by
错误的原因在于 COUNT(t1.b) 可以出现在 HAVING 中,从而导致外部查询产生聚合操作。
窗口函数(包括聚合窗口函数)的处理没有那么复杂,它们总是在当前子查询中进行聚合操作。
窗口函数的计算可能会受到系统变量 windowing_use_high_precision 的影响,该变量决定了计算窗口的操作是否确保不会丢失精度。默认启用了 windowing_use_high_precision。
对于某些移动窗口的聚合操作,可以使用反向聚合功能删除不需要的数据。这种方法可以提高性能,但可能导致精度丢失。例如,将一个很小的浮点数和一个很大的值相加,会导致这个浮点数被“遮盖”;随后对这个大值进行反向取值时,小浮点数的效果就会丢失。
反向聚合只会导致浮点数据类型的精度丢失;对于其他类型不会有影响,包括 DECIMAL 数据类型。
为了性能,MySQL 在安全的情况下总是会使用反向聚合:
对于浮点型数据,反向聚合可能导致精度丢失。默认设置可以避免反向聚合,以性能的牺牲确保了精度。如果可以丢失一定的精度,可以禁用 windowing_use_high_precision 以支持反向聚合。
对于非浮点型的数据类型,反向聚合不会产生问题,因此无论 windowing_use_high_precision 如何设置都会使用反向聚合。
windowing_use_high_precision 对于 MIN() 和 MAX() 聚合函数没有影响,因为它们永远不会使用反向聚合。
对于计算方差的 STDDEV_POP()、STDDEV_SAMP()、VAR_POP()、VAR_SAMP() 等聚合函数,可以使用优化模式或者默认模式。 优化模式可能导致最后一位小数略有不同,如果允许存在这些偏差,经用 windowing_use_high_precision 可以利用优化模式。
对于 EXPLAIN 命令,传统输出格式显示窗口执行信息过于复杂;如果想要显示相关信息,可以使用 EXPLAIN FORMAT=JSON,然后查找 windowing 元素。
如果你点击了收藏⭐,请不要忘了关注❤️、评论📝、点赞👍!
 分类导航
分类导航