

 个人中心
个人中心 退出
退出




理论:第一章:HashMap底层实现原理,红黑树,B+树,B树的结构原理,volatile关键字,CAS(比较与交换)实现原理
首先HashMap是Map的一个实现类,而Map存储形式是键值对(key,value)的。可以看成是一个一个的Entry。Entry所存放的位置是由key来决定的。
Map中的key是无序的且不可重复的,所有的key可以看成是一个set集合,如果出现Map中的key如果是自定义类的对象,则必须重写hashCode和equals方法,因为如果不重写,使用的是Object类中的hashCode和equals方法,比较的是内存地址值不是比内容。
Map中的value是无序的可重复的,所有的value可以看成是Collection集合,Map中的value如果是自定义类的对象必须重写equals方法。
至于要重写hashCode和equals分别做什么用,拿hashMap底层原理来说:
当我们向HashMap中存放一个元素(k1,v1),先根据k1的hashCode方法来决定在数组中存放的位置。
如果这个位置没有其它元素,将(k1,v1)直接放入Node类型的数组中,这个数组初始化容量是16,默认的加载因子是0.75,也就是当元素加到12的时候,底层会进行扩容,扩容为原来的2倍。如果该位置已经有其它元素(k2,v2),那就调用k1的equals方法和k2进行比较二个元素是否相同,如果结果为true,说明二个元素是一样的,用v1替换v2,如果返回值为false,二个元素不一样,就用链表的形式将(k1,v1)存放。
不过当链表中的数据较多时,查询的效率会下降,所以在JDK1.8版本后做了一个升级,hashmap就是当链表中的元素达到8并且元素数量大于64时,会将链表替换成红黑树才会树化时,会将链表替换成红黑树,来提高查找效率。因为对于搜索,插入,删除操作多的情况下,使用红黑树的效率要高一些。
原因是因为红黑树是一种特殊的二叉查找树,二叉查找树所有节点的左子树都小于该节点,所有节点的右子树都大于该节点,就可以通过大小比较关系来进行快速的检索。
在红黑树上插入或者删除一个节点之后,红黑树就发生了变化,可能不满足红黑树的5条性质,也就不再是一颗红黑树了,而是一颗普通的树,可以通过左旋和右旋,使这颗树重新成为红黑树。怕大家搞混,我把二个树之间的区别给上(红黑树与平衡二叉树的区别?https://blog.csdn.net/qfc8930858/article/details/89856274)

而且像这种二叉树结构比较常见的使用场景是Mysql二种引擎的索引.
首先B树它的每个节点都是Key.value的二元组,它的key都是从左到右递增的排序,value中存储数据。这种模式在读取数据方面的性能很高,因为有单独的索引文件,Myisam 的存储文件有三个.frm是表的结构文件,.MYD是数据文件,.MYI是索引文件。不过Myisam 也有些缺点它只支持表级锁,不支持行级锁也不支持事务,外键等,所以一般用于大数据存储。
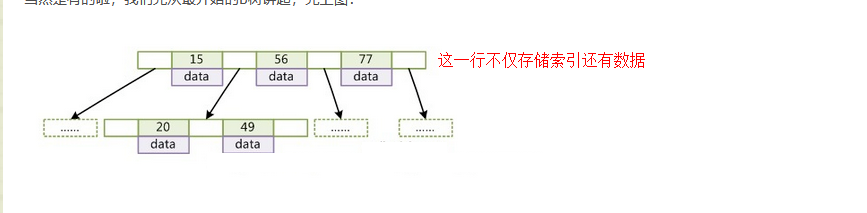
然后是InnoDB,它的存储文件相比Myisam少一个索引文件,它是以 ID 为索引的数据存储,数据现在都被存在了叶子结点,索引在非叶结点上。而这些节点分散在索引页上。在InnoDB里,每个页默认16KB,假设索引的是8B的long型数据,每个key后有个页号4B,还有6B的其他数据,那么每个页的扇出系数为16KB/(8B+4B+6B)≈1000,即每个页可以索引1000个key。在高度h=3时,s=1000^3=10亿!!也就是说,InnoDB通过三次索引页的I/O,即可索引10亿的key,而非叶节点这一行存储的索引,数量就多了,I/O的次数就少了。而Myisam在每个节点都存储数据和索引,这样就减少了每页存储的索引数量。而且InnoDB它还支持行级,表级锁,也支持事务,外键.

另外对于HashMap实际使用过程中还是会出现一些线程安全问题:
HashMap是线程不安全的,在多线程环境下,使用Hashmap进行put操作会引起死循环,导致CPU利用率接近100%,而且会抛出并发修改异常,导致原因是并发争取线程资源,修改数据导致的,一个线程正在写,一个线程过来争抢,导致线程写的过程被其他线程打断,导致数据不一致。
HashTable是线程安全的,只不过实现代价却太大了,简单粗暴,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把大锁。多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞,相当于将所有的操作串行化,在竞争激烈的并发场景中性能就会非常差。
为了应对hashmap在并发环境下不安全问题可以使用,ConcurrentHashMap大量的利用了volatile,CAS等技术来减少锁竞争对于性能的影响。
在JDK1.7版本中ConcurrentHashMap避免了对全局加锁,改成了局部加锁(分段锁),分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。不过这种结构的带来的副作用是Hash的过程要比普通的HashMap要长。
所以在JDK1.8版本中CurrentHashMap内部中的value使用volatile修饰,保证并发的可见性以及禁止指令重排,只不过volatile不保证原子性,使用为了确保原子性,采用CAS(比较交换)这种乐观锁来解决。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。
如果内存地址里面的值和A的值是一样的,那么就将内存里面的值更新成B。CAS是通过无限循环来获取数据的,若果在第一轮循环中,a线程获取地址里面的值被b线程修改了,那么a线程需要自旋,到下次循环才有可能机会执行。
volatile有三个特性:可见性,不保证原子性,禁止指令重排。
可见性:线程1从主内存中拿数据1到自己的线程工作空间进行操作(假设是加1)这个时候数据1已经改为数据2了,将数据2写回主内存时通知其他线程(线程2,线程3),主内存中的数据1已改为数据2了,让其他线程重新拿新的数据(数据2)。
不保证原子性:线程1从主内存中拿了一个值为1的数据到自己的工作空间里面进行加1的操作,值变为2,写回主内存,然后还没有来得及通知其他线程,线程1就被线程2抢占了,CPU分配,线程1被挂起,线程2还是拿着原来主内存中的数据值为1进行加1,值变成2,写回主内存,将主内存值为2的替换成2,这时线程1的通知到了,线程2重新去主内存拿值为2的数据。
禁止指令重排:首先指令重排是程序执行的时候不总是从上往下执行的,就像高考答题,可以先做容易的题目再做难的,这时做题的顺序就不是从上往下了。禁止指令重排就杜绝了这种情况。
(一般面试官开始问你会从java基础问起,一问大多数会问到集合这一块,而集合问的较多的是HashMap,这个时候你就可以往这些方向带着面试官问你,而且扩展的深度也够,所以上面的干货够你说个十来分钟吧,第一个问题拿下后,面试官心里至少简单你的基础够扎实,第一印象分就留下了)
 分类导航
分类导航